IBM SPSS Modeler
///
Przygotowanie danych do modelowania

IBM SPSS MODELER umożliwia przygotowanie danych do modelowania.
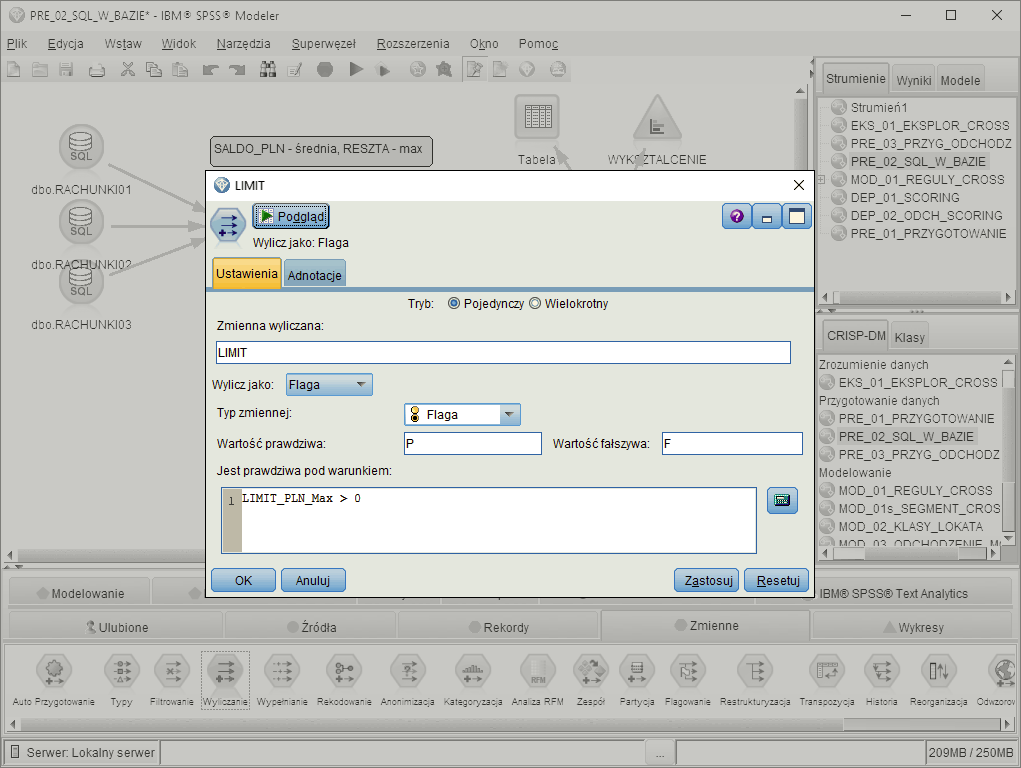
Wyliczanie
Wykonywanie obliczeń przy pomocy przekształceń algebraicznych, funkcji i innych metod.Program pozwala wyliczać nowe cechy poprzez wykonywanie przekształceń algebraicznych, wykorzystywanie funkcji operacji na danych, definiowanie warunków logicznych, redukowanie liczby kategorii zmiennej itp.
W konstruktorze wyrażeń, dostępna jest szeroka gama wbudowanych funkcji, w tym arytmetycznych, logicznych, operujących na ciągach tekstowych, na datach, funkcji konwersji czy prawdopodobieństwa. Możliwe jest także korzystanie z funkcji bazodanowych.
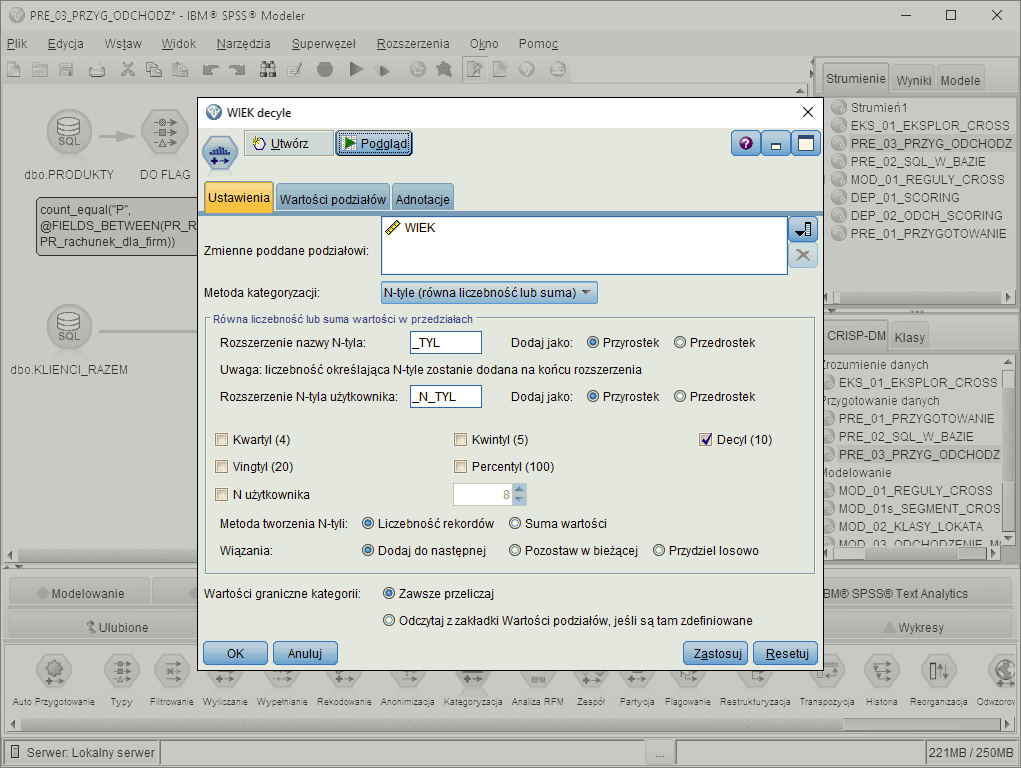
Rekodowanie i kategoryzacja
Podział na kategorie wartości cech ilościowych oraz zmiana sposobu kodowania wartości cech jakościowych.Program daje możliwość przypisania nowych wartości do istniejących kolumn w tabeli, zmiany sposobu kodowania wartości lub łączenia kilku wartości w nową wartość. Możliwy jest również automatyczny podział cech ilościowych na kategorie za pomocą wybranej metody kategoryzacji.
Program umożliwia utworzenie przedziałów o ustalonej szerokości, przedziałów o równej liczebności lub równych co do sum, a także podział wartości cech w oparciu o wskazaną liczbę odchyleń standardowych od średniej. Podział może się też dokonać w oparciu o algorytm rangowania bądź przy kontroli kategorialnej cechy nadzorującej.
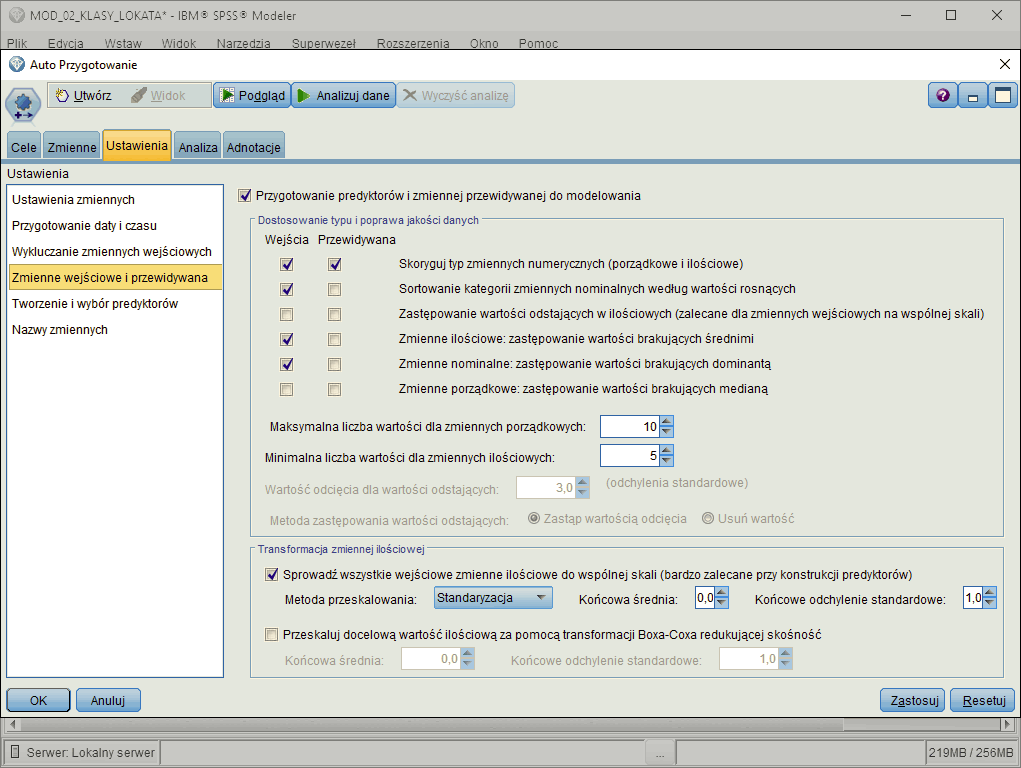
Automatyczne przygotowanie danych
Automatyczne przygotowanie danych do analiz poprzez poprawę jakości danych, normalizowanie wartości, zmianę sposobu kodowania itp.Program pozwala w sposób automatyczny dokonać poprawy jakości danych poprzez korektę poziomu pomiaru cech numerycznych, zastępowanie wartości odstających, zastępowanie braków danych.
Program automatycznie wyklucza cechy o stałych wartościach, zmienne o zbyt dużej liczbie braków czy zmienne o zbyt dużej liczbie unikatowych kategorii. Program umożliwia automatyczne wykonanie przekształceń, w celu sprowadzenia cech do wspólnej skali czy też wyliczenia czasu trwania z kolumn w formacie daty i czasu.
Wybór predyktorów
Ocena siły wpływu predyktorów na wartości przewidywane i ich automatyczna selekcja.Program umożliwia automatyczny wybór predyktorów do budowy modeli predykcyjnych.
Algorytm odfiltrowuje nieistotne i problematyczne predyktory, takie jak cechy ze zbyt dużą liczbą braków danych lub zbyt dużą liczbą kategorii. Umożliwia sortowanie pozostałych cech i przypisanie rang na podstawie siły związku. Następnie określa podzbiór predyktorów użytecznych dla modeli predykcyjnych.
Ważność predyktorów może być określana na podstawie miar takich jak: chi-kwadrat Pearsona, iloraz wiarygodności chi-kwadrat, V-Cramera, lambda, statystyka F i inne.

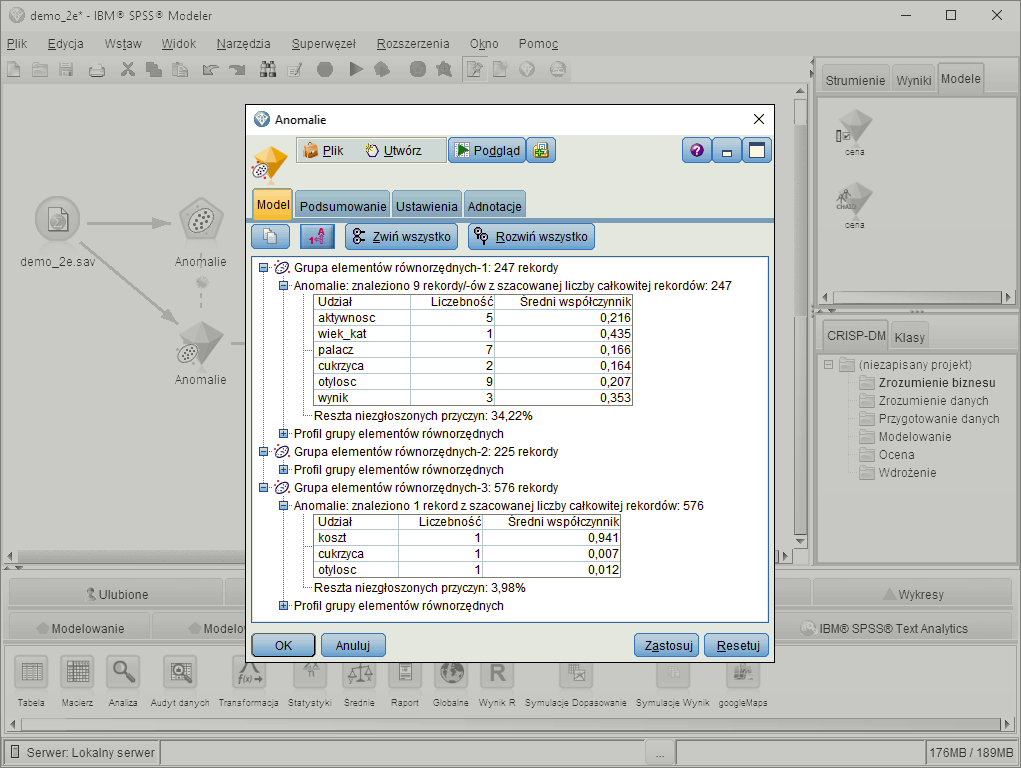
Detekcja anomalii
Identyfikacja rekordów nietypowych w ujęciu wielowymiarowym.Algorytm wykrywania anomalii może analizować duże liczby zmiennych, by wykryć skupienia lub grupy podobnych rekordów. Każdy rekord jest następnie porównywany z innymi rekordami w tej samej grupie w celu wykrycia ewentualnych anomalii.
Każdemu rekordowi przypisuje się indeks anomalii, określający jak bardzo dany rekord różni się od rekordu typowego w grupie, do której jest przypisany. Wyliczany jest również wpływ każdej ze zmiennych na indeks anomalii.