IBM SPSS Data Collection
///
Dystrybucja wyników badań

W IBM SPSS DATA COLLECTION wyniki badania wraz z danymi dotyczącymi sposobu wypełniania ankiet mogą być eksportowanie do postaci zbioru danych.
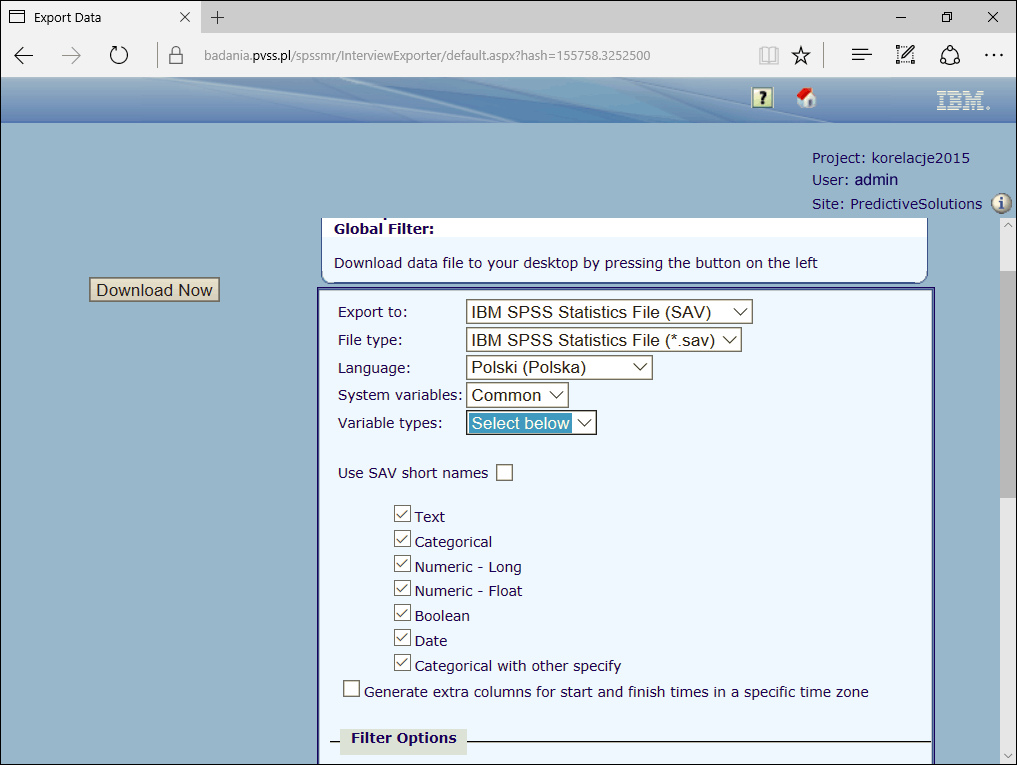
Eksport wyników
Eksport wyników badania do postaci zbioru danych.Możliwy jest eksport wyników badania do formatu IBM SPSS Statistics (SAV), plików tekstowych i innych formatów. Eksportowane pliki wynikowe spakowane są za pomocą kompresora zip.
Program umożliwia wybór wersji kwestionariusza, który ma być użyty podczas eksportu danych oraz wybór kontekstu metadanych. Możliwe jest także wykorzystanie skróconych etykiet zmiennych oraz wskazanie wersji językowej, w jakiej mają zostać pobrane wyniki badania.
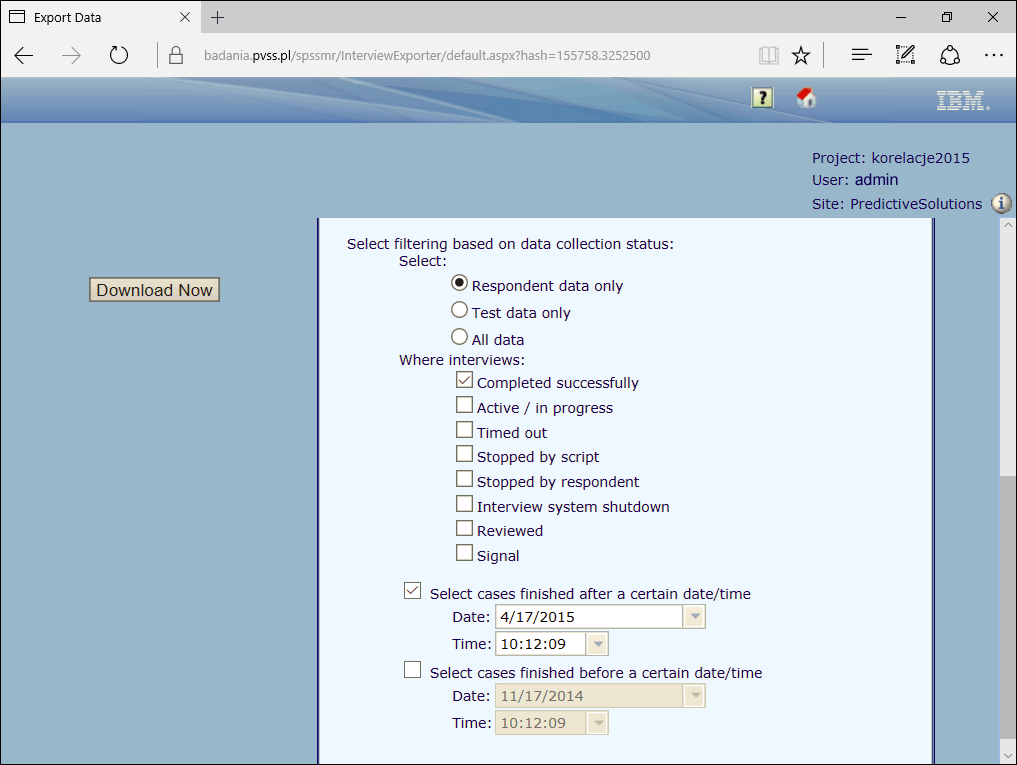
Filtrowanie wyników na etapie eksportu
Ograniczenie zbioru danych podczas pobierania danych z badania do wybranych zmiennych i obserwacji.Eksport może dotyczyć wszystkich zmiennych, łącznie ze zmiennymi systemowymi, lub tylko zmiennych związanych z treścią ankiety. Możliwe jest też filtrowanie zmiennych ze względu na ich typ (zmienne tekstowe, numeryczne, zmienne w formacie daty itd.).
Program umożliwia selekcję obserwacji ze względu na tryb wypełniania (testowe lub produkcyjne), status wywiadu (zakończony, przerwany itp.) oraz zakres czasowy wywiadu.

Informacje o sposobie wypełniania ankiety
Rejestrowanie i udostępnianie danych dotyczących sposobu wypełniania ankiety, czyli zmiennych systemowych.Program nadaje każdemu respondentowi unikalny numer. Program zapewnia dostęp do informacji o tym jaki typ ankiety wypełniał respondent, o wersji kwestionariusza, jaka była wykorzystana podczas wywiadu, o czasie rozpoczęcia i zakończenia wywiadu, o aktualnym statusie wywiadu (zakończony, przerwany itp.).
Dostępna jest też informacja, na którym pytaniu respondent zakończył wypełnianie ankiety. Zmienne systemowe mogą być dołączone do zbioru danych z wynikami badania.
Automatyczny opis zmiennych
Automatyczne dostosowanie właściwości zmiennych i ich opisu na potrzeby późniejszych analiz.Właściwości zmiennych w zbiorze wynikowym odzwierciedlają rzeczywisty typ danych oraz ustawienia poczynione na etapie projektowania ankiety. Nazwy zmiennych pochodzą od nazw pytań z kwestionariusza.
Typ zmiennej oraz poziom pomiaru jest automatycznie dostosowany do typu pytania (np. pytanie o datę utworzy zmienną daty). Etykieta zmiennej odzwierciedla treść pytania kwestionariuszowego, a etykiety wartości – treść kafeterii odpowiedzi.
Kody braków danych użytkownika są zdefiniowane zgodnie z wcześniejszymi ustawieniami.
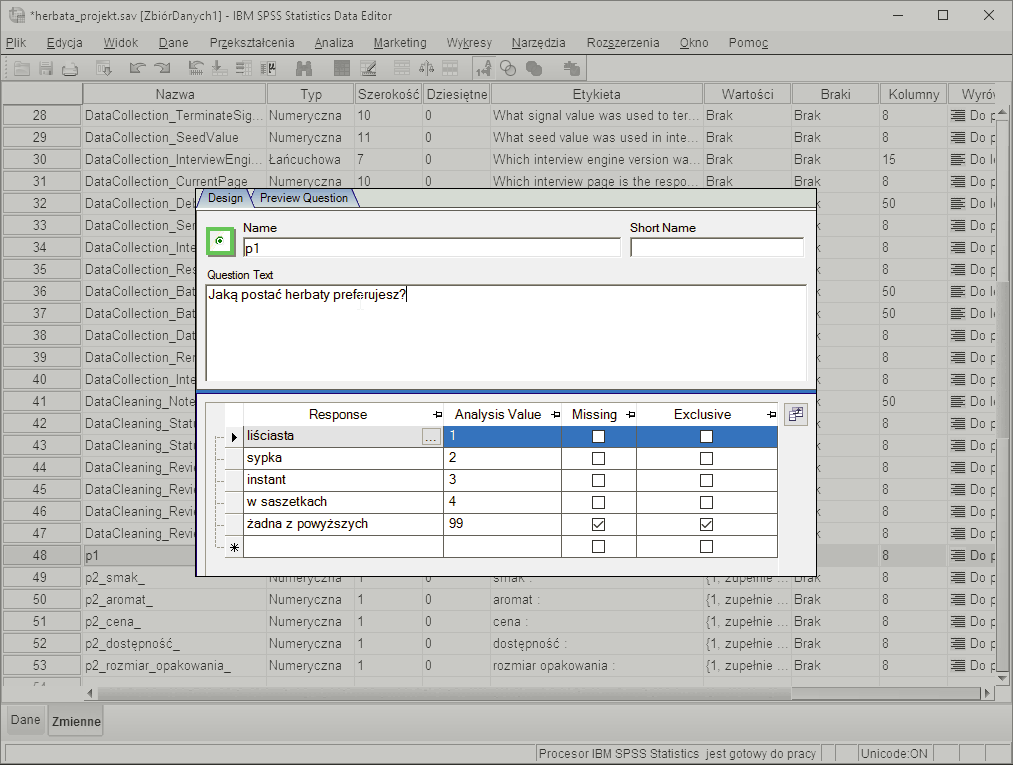
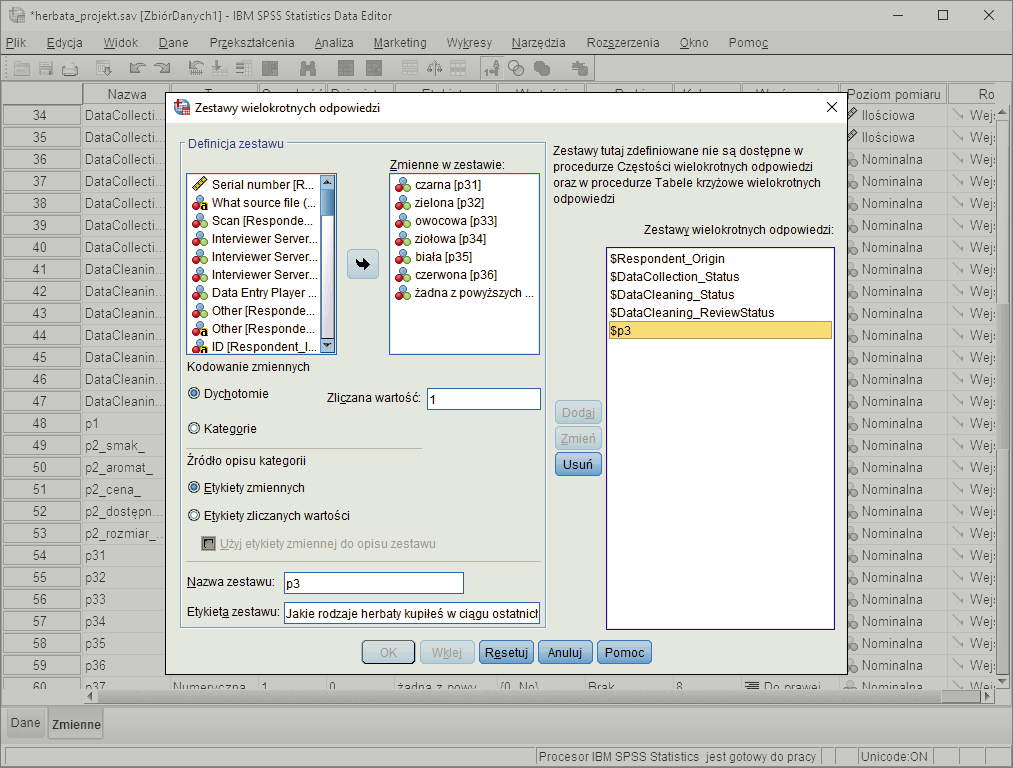
Automatyczne przygotowanie danych z pytań wielokrotnego wyboru
Automatyczne przygotowanie do analiz danych pochodzących z pytań wielokrotnego wyboru.Dane pochodzące z pytań wielokrotnego wyboru są kodowane dychotomicznie – dla każdego elementu kafeterii odpowiedzi tworzona jest osobna zmienna, która przyjmuje wartości „0”, gdy element nie został wybrany lub „1”, gdy został wybrany.
Dla tego rodzaju pytań, program automatycznie tworzy zestawy wielokrotnych odpowiedzi, co pozwala na połączenie ze sobą informacji pochodzących z wielu zmiennych.