IBM SPSS Modeler
///
Dostęp i zarządzanie danymi

IBM SPSS MODELER umożliwia dostęp do danych zarówno z serwerów lokalnych, jak i zewnętrznych.
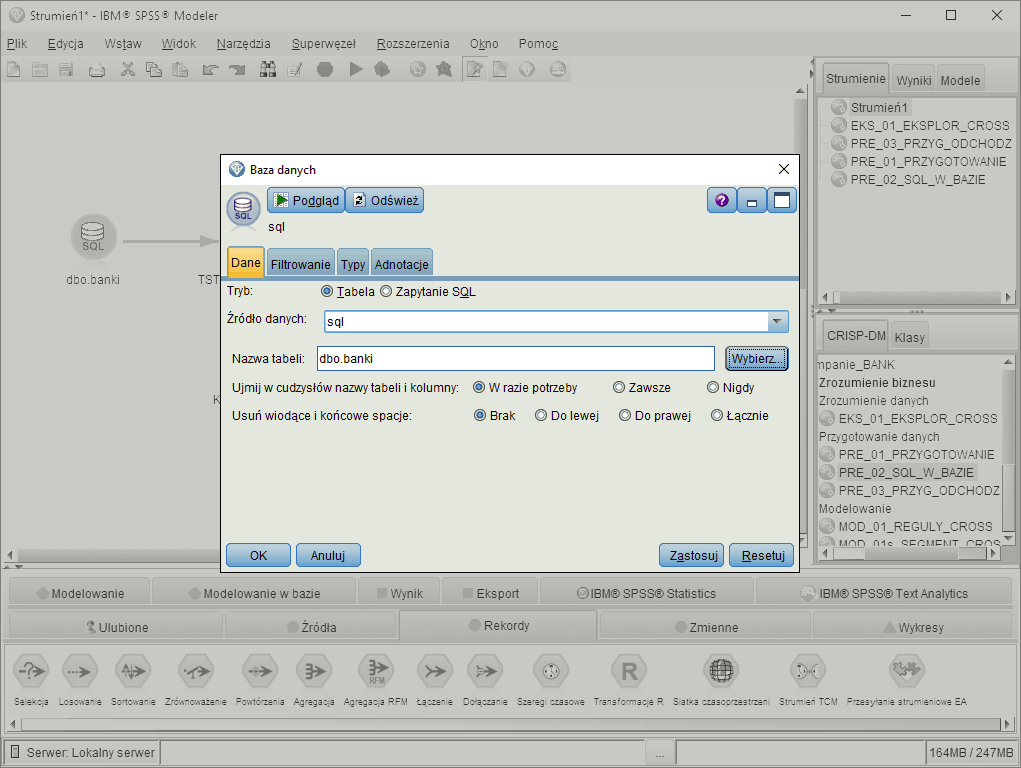
Integracja z bazami danych
Praca z danymi w bazach danych poprzez tłumaczenie własnych poleceń na kod SQL oraz samodzielne tworzenie zapytań SQL.Program umożliwia dostęp do danych z baz danych takich jak Microsoft SQL Server, DB2, Oracle i inne. Po nawiązaniu połączenia ze źródłem danych można wybrać zmienne z określonej tabeli lub widoku.
Operacje takie jak: losowanie, agregacja, selekcja rekordów oraz wyliczanie nowych, przekształcanie istniejących atrybutów mogą być realizowane bezpośrednio w bazie. Operacje na danych definiowane przy użyciu interfejsu programu mogą być automatycznie tłumaczone na kod SQL i przesyłane do realizacji w systemie bazodanowym. Możliwe jest też samodzielne tworzenie poleceń SQL.
Pobieranie danych
Import danych z różnych źródeł – m.in. plików IBM SPSS Statistics, arkuszy kalkulacyjnych jak Excel czy plików tekstowych.Podczas importu pliku IBM SPSS Statistics, program umożliwia wybór obsługi etykiet zmiennych i wartości.
W czasie importowania danych z programu Excel, program pozwala na wybór arkusza, określenie zakresu komórek w arkuszu oraz wczytanie nagłówków danych.
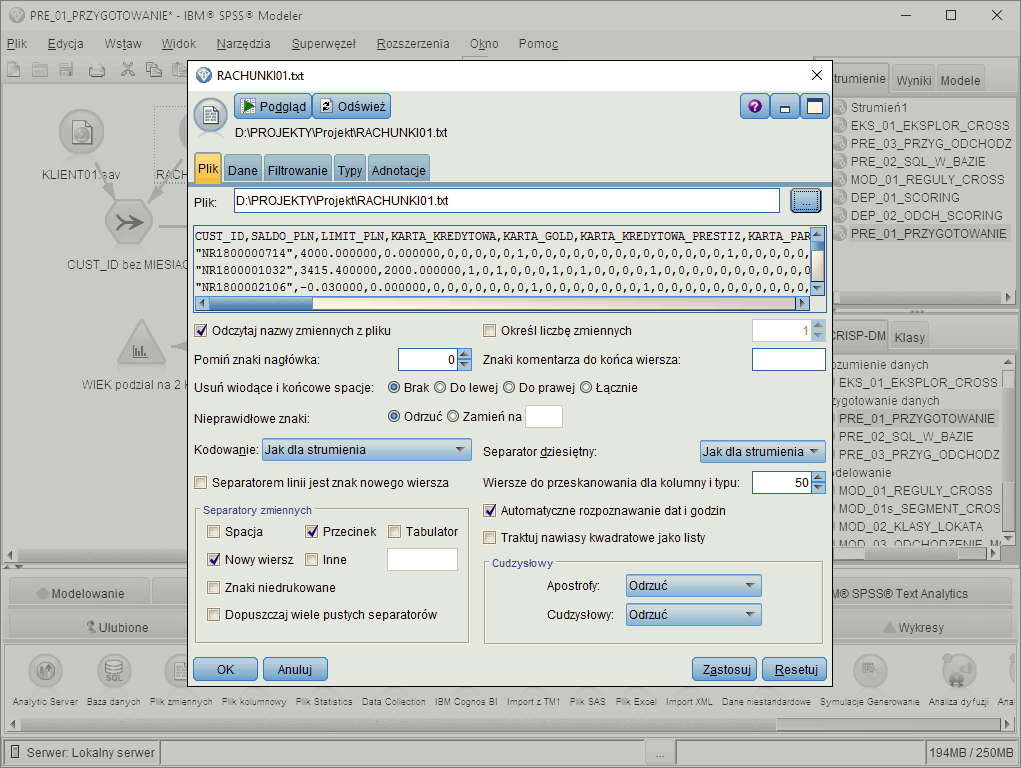
Podczas importu danych z pliku tekstowego program daje możliwość podglądu danych i wprowadzenia własnych ustawień importu (m.in. odczytywanie nazw zmiennych z nagłówków kolumn, usuwanie niepotrzebnych spacji, automatyczne rozpoznawanie dat i godzin).
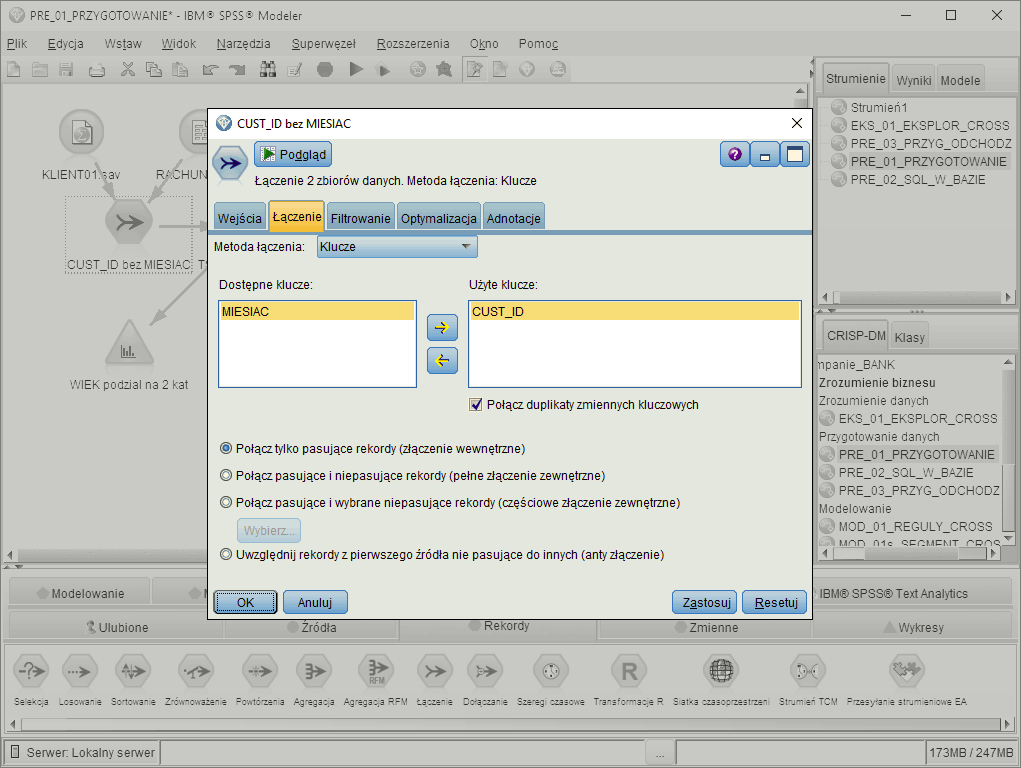
Łączenie danych
Łączenie danych pochodzących z wielu plików lub tabel baz danych za pomocą dołączania rekordów lub dodawania kolumn.Program pozwala na łączenie plików danych np. z różnych okresów, różnych regionów. Istnieje możliwość utworzenia zmiennej identyfikującej źródło każdej obserwacji. Program umożliwia także łączenie różnych tabel z baz danych z użyciem metod łączenia jeden-do-jeden, czy jeden-do-wielu oraz kontrolę sposobu łączenia tabel (sprzężenia wewnętrzne, zewnętrzne itp.).
Do poprawnego dopasowania obserwacji w dwóch tabelach można użyć prostych lub złożonych kluczy łączenia lub łączyć zgodnie z kolejnością występowania rekordów. Łączenie danych jest możliwe nawet wtedy, gdy występuje częściowe niedopasowanie zbiorów.
Selekcja i filtrowanie
Selekcja rekordów oraz wybór kolumn do analiz.Program umożliwia wyselekcjonowanie do dalszych analiz rekordów spełniających dowolny zdefiniowany przez użytkownika warunek. Podczas tworzenia warunków selekcji, możliwe jest korzystanie z konstruktora wyrażeń, jak również z szerokiego zakresu dostępnych wewnętrznych funkcji programu lub funkcji bazodanowych.
Narzędzie umożliwia sprawdzenie poprawności utworzonej formuły. Istnieje też możliwość zmiany nazwy lub wykluczenia zmiennych w dowolnym punkcie strumienia.

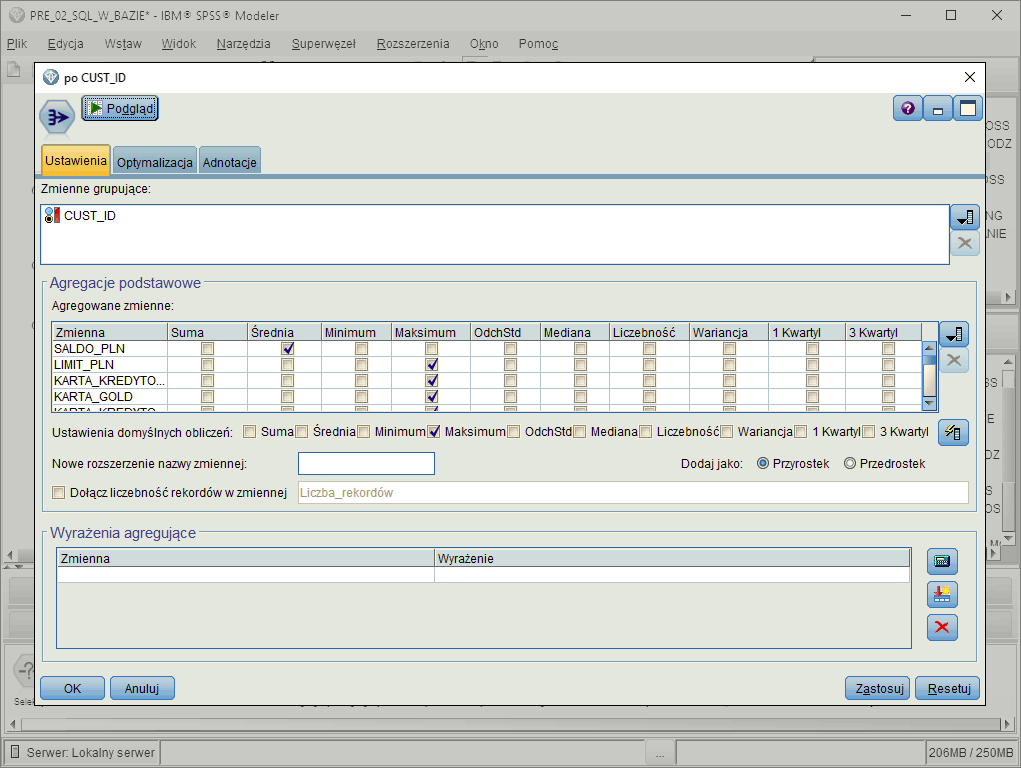
Agregacja danych
Agregacja danych poprzez wyliczenie statystyk i miar dla wskazanych wymiarów danych.Program pozwala wyliczać statystyki dla grup rekordów w oparciu o wskazane atrybuty będące wymiarami agregacji. Jeśli atrybut grupujący nie zostanie zdefiniowany, statystyki zostaną obliczone dla wszystkich rekordów, traktowanych jako jedna grupa.
Dostępne funkcje agregujące obejmują takie statystyki jak: średnia, mediana, suma, wariancja, odchylenie standardowe, minimum, maksimum, 1 kwartyl, 3 kwartyl. Możliwe jest również zapisanie zmiennej wskazującej na liczbę rekordów w każdej grupie.